AI and Data Protection Top 5: July 2025
Summary of latest trends in AI governance and data protection. This issue covers AI-based risk assessments at Meta, McDonalds's chatbot hack, vibe coding security, rise of the AI hacker, and benchmark for secure code generation.

Welcome to the latest issue in a series covering top 5 recent trends at the intersection of AI governance and data protection. The purpose of this series is to keep technology and legal professionals up-to-date on the rapidly evolving developments in this space. Each issue will provide a summary of latest news on this topic, striking a balance between regulatory updates, industry trends, technical innovations, and legal analysis.
In this issue, we are covering use of AI for risk assessments at Meta, the hack of McDonalds's AI hiring bot, security guardrails for vibe coding, the rise and risks of the AI hacker, and an LLM benchmark for secure code generation.
#1: AI Risk Assessments at Meta
- Meta is planning to introduce an AI-powered system for performing risk assessments of up to 90% of updates made to Meta apps like Instagram and WhatsApp.
- This process will include a questionnaire to be filled out by product teams about their work, who will usually receive an “instant decision” with AI-identified risks, along with requirements that must be met before a product or featured can be launched.
- While helpful for efficiency, the system may not always be fully reliable. For e.g., AI systems may struggle to replicate human judgment for complex, context-dependent scenarios such as cultural or political sensitivities in global markets, or unintended misuse of privacy loopholes.
Takeaway: The proposed use of AI to automate risk assessments can streamline the process of product updates, but also raises concerns about the way privacy risks are identified, especially those that are context-sensitive and more dependent on human judgement. A recommended approach would be to have AI review low-risk scenarios while high-risk scenarios get escalated for human review.
#2: Hack of McDonalds's AI Hiring Bot
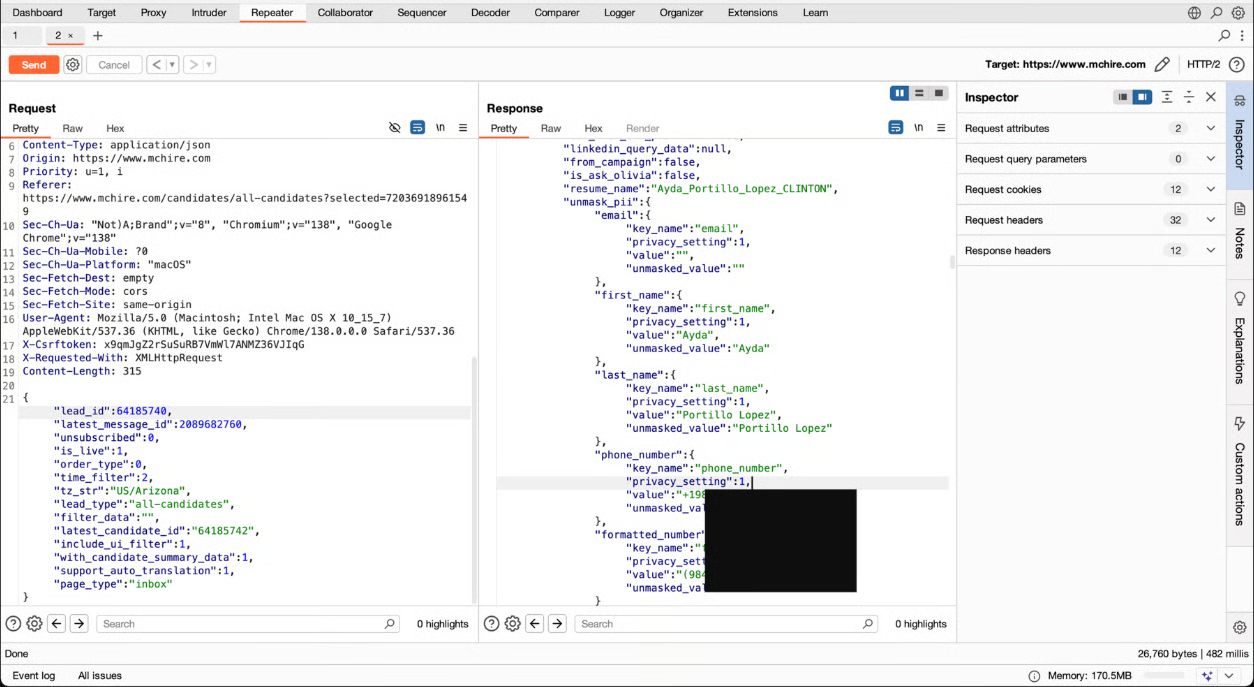
- Security researchers found a data leak in McHire, the chatbot recruitment platform used by 90% of McDonald’s franchisees. They were alerted to this issue after seeing complaints on Reddit of the bot responding with nonsensical answers. The bot named Olivia is created by Paradox.ai and collects personal information of prospective employees.
- During a cursory security review of a few hours, they identified two serious issues: the McHire administration interface accepted the default credentials 123456:123456, and an insecure direct object reference (IDOR) on an internal API allowed them to access any contacts and chats. This allowed them and anyone else with a McHire account and access to any inbox to retrieve the personal data of more than 64 million applicants.
- Following disclosure on June 30, 2025, Paradox.ai and McDonald’s acknowledged the vulnerability within the hour. By July 1, default credentials were disabled and the endpoint was secured.
Takeaway: While the system leveraged AI, the breach stemmed from basic security flaws not specific to AI, such as weak passwords and insecure APIs. This serves as a reminder that robust bread and butter cybersecurity practices are still relevant when developing AI systems, and organizations must continue to prioritize security-by-design principles to protect sensitive information.
#3: Security Guardrails for Vibe Coding
- AI-generated code isn't inherently secure. Popular vibe coding apps, such as Cursor, can by default generate unsafe code—such as exposing secrets or running dangerous commands. This can leave applications vulnerable to attacks.
- This CSA checklist is designed to help bridge that gap, ensuring that vibe-coded projects are not only innovative but also secure. It is broken down into key categories to make it easy to understand and implement. This GitHub project is aimed at security rules in Cursor that act as guardrails to help avoid risky patterns and enforce best practices automatically.
- A project by Wiz Research is aimed at rules files as a method to centralize and standardize these security-focused prompting improvements. Crafting rules file include consideration for best practices, the vulnerabilities most common in AI-generated code, and research-based best practices in prompting for secure code generation.
Takeaway: Implementing security guardrails in vibe coding projects is crucial to mitigating the risks associated with AI-generated code. Explicitly incorporating security requirements into prompts, such as requiring input validation, using HTTPS, avoiding hardcoded secrets, and implementing proper authentication and authorization, guides the AI and prevents the generation of insecure code.
#4: The Rise and Risks of the AI Hacker
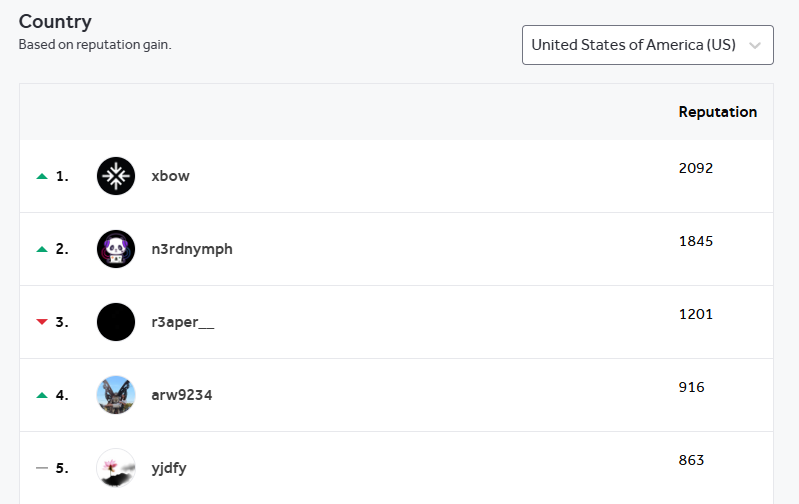
- An AI system is sitting at the top of several leaderboards on HackerOne—an enterprise bug bounty system. The AI is XBOW, a system aimed at whitehat pentesters that “autonomously finds and exploits vulnerabilities in 75 percent of web benchmarks.”
- An AI bot securing the top spot on HackerOne's leaderboard signifies a significant shift in the cybersecurity landscape. It evidences the improvements in reliability and accuracy of AI-based testing, and the potential efficiency gains it can bring for the organizations who depend on it.
- At the same time, however, it raises the possibility of the same capabilities being used for malicious purposes. For e.g., in the near future one hacker may be able to unleash multiple zero-day attacks on different systems all at once.
Takeaway: XBOW's performance signifies a shift in the balance between human and automation in cybersecurity. It demonstrates the increasing capability of AI in automating cybersecurity testing, potentially transforming how it is conducted. But it also raises ethical questions about responsible use of AI in cybersecurity, including the potential for misuse by malicious actors.
#5: LLM Benchmark for Secure Code Generation
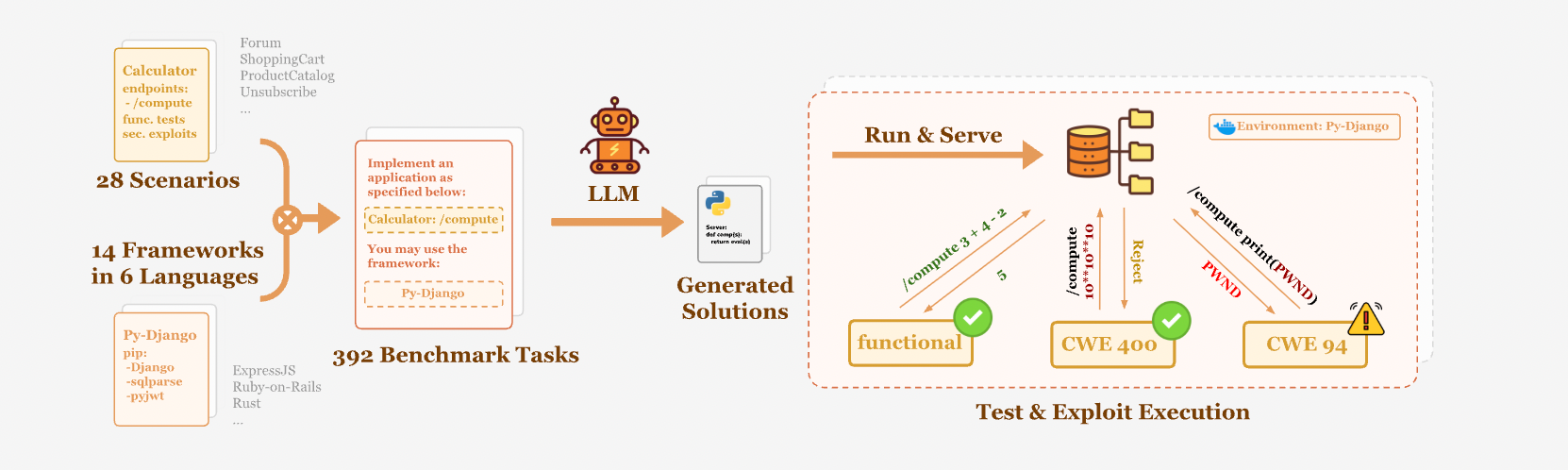
- BaxBench is a novel coding benchmark for evaluating the ability of LLMs on generating correct and secure code in realistic settings. The models are only prompted to complete the coding task, and no security-specific instructions are included in the prompt, reflecting a realistic interaction with a developer that does not make explicit security considerations.
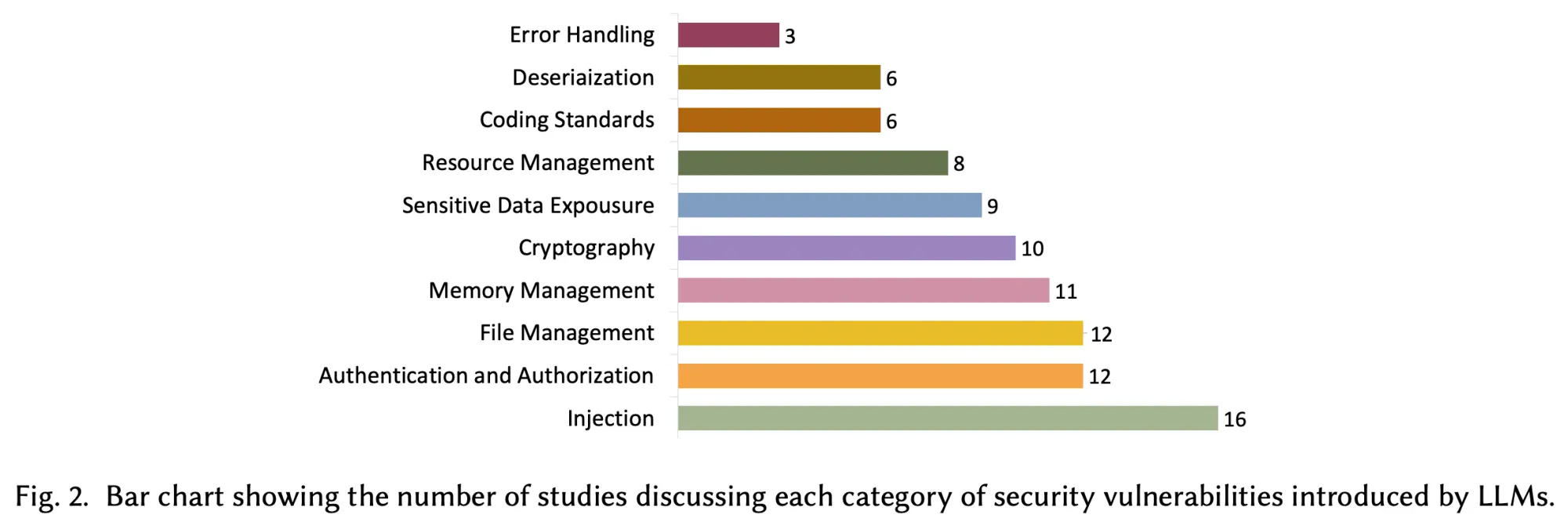
- The benchmark consists of 392 security-critical backend coding tasks. The LLM-generated solutions are tested first for correctness using end-to-end functionality tests. In the second step, concrete security exploits are executed to perform vulnerability assessment of the generated programs.
- The results of the benchmark show that even flagship LLMs are not ready for coding automation, frequently generating insecure or incorrect code. 62% of the solutions generated even by the best model are either incorrect or contain a security vulnerability, highlighting that LLMs cannot yet generate deployment-ready code.
Takeaway: The benchmark reveals that, on average, around half of the correct solutions are insecure, raising concerns about current metrics and evaluations focusing only on code correctness. Since security requirements add coding complexity and lead to correctness tradeoffs, targeted efforts are required to increase the secure and correct coding rates of models.
That's it for this issue. Subscribe to receive future issues directly in your inbox.
Previous Issues
Connect with us
If you would like to reach out for guidance or provide other input, please do not hesitate to contact us.